API Reference¶
This is intended for users of pyexcel.
Note
sphinx on ReadTheDocs cannot produce api docs. Please read it from [pypi](http://pythonhosted.org/pyexcel/api.html)
Signature functions¶
These flags can be passed on to control plugin behaviors:
auto_detect_int¶
Automatically convert float values to integers if the float number has no decimal values(e.g. 1.00). By default, it does the detection. Setting it to False will turn on this behavior
It has no effect on pyexcel-xlsx because it does that by default.
auto_detect_float¶
Automatically convert text to float values if possible. This applies only pyexcel-io where csv, tsv, csvz and tsvz formats are supported. By default, it does the detection. Setting it to False will turn on this behavior
auto_detect_datetime¶
Automatically convert text to python datetime if possible. This applies only pyexcel-io where csv, tsv, csvz and tsvz formats are supported. By default, it does the detection. Setting it to False will turn on this behavior
library¶
Name a pyexcel plugin to handle a file format. In the situation where multiple plugins were pip installed, it is confusing for pyexcel on which plugin to handle the file format. For example, both pyexcel-xlsx and pyexcel-xls reads xlsx format. Now since version 0.2.2, you can pass on library=”pyexcel-xls” to handle xlsx in a specific function call.
Alternatively, you could uninstall the unwanted pyexcel plugin using pip.
Obtaining data from excel file¶
get_array(**keywords) |
Obtain an array from an excel source |
get_dict([name_columns_by_row]) |
Obtain a dictionary from an excel source |
get_records([name_columns_by_row]) |
Obtain a list of records from an excel source |
get_book_dict(**keywords) |
Obtain a dictionary of two dimensional arrays |
get_book(**keywords) |
Get an instance of Book from an excel source |
get_sheet(**keywords) |
Get an instance of Sheet from an excel source |
Saving data to excel file¶
save_as(**keywords) |
Save a sheet from a data srouce to another one |
save_book_as(**keywords) |
Save a book from a data source to another one |
Cookbook¶
merge_csv_to_a_book(filelist[, outfilename]) |
merge a list of csv files into a excel book |
merge_all_to_a_book(filelist[, outfilename]) |
merge a list of excel files into a excel book |
split_a_book(file_name[, outfilename]) |
Split a file into separate sheets |
extract_a_sheet_from_a_book(file_name, sheetname) |
Extract a sheet from a excel book |
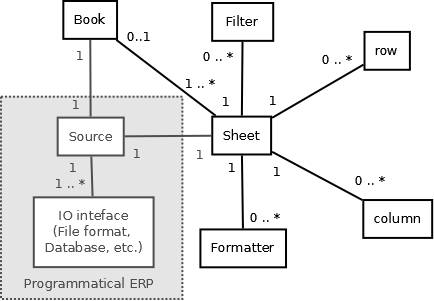
Book¶
Here’s the entity relationship between Book, Sheet, Row and Column
Attribute¶
Book.number_of_sheets() |
Return the number of sheets |
Book.sheet_names() |
Return all sheet names |
Conversions¶
Book.to_dict() |
Convert the book to a dictionary |
Save changes¶
Book.save_to(source) |
Save to a writeable data source |
Book.save_as(filename) |
Save the content to a new file |
Book.save_to_memory(file_type[, stream]) |
Save the content to a memory stream |
Book.save_to_database(session, tables[, ...]) |
Save data in sheets to database tables |
Sheet¶
Constructor¶
Sheet([sheet, name, name_columns_by_row, ...]) |
Two dimensional data container for filtering, formatting and iteration |
Save changes¶
Sheet.save_to(source) |
Save to a writeable data source |
Sheet.save_as(filename, **keywords) |
Save the content to a named file |
Sheet.save_to_memory(file_type[, stream]) |
Save the content to memory |
Sheet.save_to_database(session, table[, ...]) |
Save data in sheet to database table |
Attributes¶
Sheet.row |
Row representation. |
Sheet.column |
Column representation. |
Sheet.number_of_rows() |
Number of rows in the data sheet |
Sheet.number_of_columns() |
Number of columns in the data sheet |
Sheet.row_range() |
Utility function to get row range |
Sheet.column_range() |
Utility function to get column range |
Iteration¶
Sheet.rows() |
Returns a top to bottom row iterator |
Sheet.rrows() |
Returns a bottom to top row iterator |
Sheet.columns() |
Returns a left to right column iterator |
Sheet.rcolumns() |
Returns a right to left column iterator |
Sheet.enumerate() |
Iterate cell by cell from top to bottom and from left to right |
Sheet.reverse() |
Opposite to enumerate |
Sheet.vertical() |
Default iterator to go through each cell one by one from |
Sheet.rvertical() |
Default iterator to go through each cell one by one from rightmost |
Cell access¶
Sheet.cell_value(row, column[, new_value]) |
Random access to the data cells |
Sheet.__getitem__(aset) |
Row access¶
Sheet.row_at(index) |
Gets the data at the specified row |
Sheet.set_row_at(row_index, data_array[, ...]) |
Update a row data range |
Sheet.delete_rows(row_indices) |
Delete one or more rows |
Sheet.extend_rows(rows) |
Take ordereddict to extend named rows |
Column access¶
Sheet.column_at(index) |
Gets the data at the specified column |
Sheet.set_column_at(column_index, data_array) |
Updates a column data range |
Sheet.delete_columns(column_indices) |
Delete one or more columns |
Sheet.extend_columns(columns) |
Take ordereddict to extend named columns |
Data series¶
Any column as row name¶
Sheet.name_columns_by_row(row_index) |
Use the elements of a specified row to represent individual columns |
Sheet.rownames |
Return row names |
Sheet.named_column_at(name) |
Get a column by its name |
Sheet.set_named_column_at(name, column_array) |
Take the first row as column names |
Sheet.delete_named_column_at(name) |
Works only after you named columns by a row |
Any row as column name¶
Sheet.name_rows_by_column(column_index) |
Use the elements of a specified column to represent individual rows |
Sheet.colnames |
Return column names |
Sheet.named_row_at(name) |
Get a row by its name |
Sheet.set_named_row_at(name, row_array) |
Take the first column as row names |
Sheet.delete_named_row_at(name) |
Take the first column as row names |
Formatting¶
Sheet.format(formatter[, on_demand]) |
Apply a formatting action for the whole sheet |
Sheet.apply_formatter(aformatter) |
Apply the formatter immediately. |
Sheet.add_formatter(aformatter) |
Add a lazy formatter. |
Sheet.remove_formatter(aformatter) |
Remove a formatter |
Sheet.clear_formatters() |
Clear all formatters |
Sheet.freeze_formatters() |
Apply all added formatters and clear them |
Filtering¶
Sheet.filter(afilter) |
Apply the filter with immediate effect |
Sheet.add_filter(afilter) |
Apply a filter |
Sheet.remove_filter(afilter) |
Remove a named filter |
Sheet.clear_filters() |
Clears all filters |
Sheet.freeze_filters() |
Apply all filters and delete them |
Conversion¶
Sheet.to_array() |
Returns an array after filtering |
Sheet.to_dict([row]) |
Returns a dictionary |
Sheet.to_records([custom_headers]) |
Returns the content as an array of dictionaries |
Anti-conversion¶
dict_to_array(*arg, **keywords) |
|
from_records(*arg, **keywords) |
Transformation¶
Sheet.transpose() |
Roate the data table by 90 degrees |
Sheet.map(custom_function) |
Execute a function across all cells of the sheet |
Sheet.region(topleft_corner, bottomright_corner) |
Get a rectangle shaped data out |
Sheet.cut(topleft_corner, bottomright_corner) |
Get a rectangle shaped data out and clear them in position |
Sheet.paste(topleft_corner[, rows, columns]) |
Paste a rectangle shaped data after a position |
Row access¶
NamedRow(matrix) |
Series Sheet would have Named Row instead of Row |
NamedRow.format([row_index, formatter, ...]) |
Format a row |
NamedRow.select(names) |
Delete row indices other than specified |
Column access¶
NamedColumn(matrix) |
Series Sheet would have Named Column instead of Column |
NamedColumn.format([column_index, ...]) |
Format a column |
NamedColumn.select(names) |
Delete columns other than specified |
Data formatters¶
ColumnFormatter(column_index, formatter) |
Apply formatting on columns |
NamedColumnFormatter(column_index, formatter) |
Apply formatting using named columns |
RowFormatter(row_index, formatter) |
Row Formatter |
NamedRowFormatter(row_index, formatter) |
Formatting rows using named rows |
SheetFormatter(formatter) |
Apply the formatter to all cells in the sheet |
Data Filters¶
ColumnFilter(indices) |
Filters out a list of columns |
SingleColumnFilter(index) |
Filters out a single column index |
OddColumnFilter() |
Filters out odd indexed columns |
EvenColumnFilter() |
Filters out even indexed columns |
ColumnValueFilter(func) |
Filters out rows based on its row values |
RowFilter(indices) |
Filters a list of rows |
SingleRowFilter(index) |
Filters out a single row |
OddRowFilter() |
Filters out odd indexed rows |
EvenRowFilter() |
Filters out even indexed rows |
RowValueFilter(func) |
Filters out rows based on its row values |
RegionFilter(row_slice, column_slice) |
Filter on both row index and column index |